Erasure of Information from Neural Representations
Description
Neural representations often contain information about attributes considered private or should not play a role in the decision-making process. This problem leads to the question: can we remove such information from neural representations to make the decision-making process not rely on such information, often spurious, to make such a process fairer and more precise?
This is where the Spectral Attribute RemovaL (SAL) comes to play. SAL erases information from neural representations by projecting them into a subspace where the correlation between these attributes and the projected representations is minimal. There is a simple way to do it by “flipping singular value decomposition on its head” – we start with the covariance matrix of the neural representations coupled with the protected attributes, and then prune away the principal directions (which are found through SVD) with the largest covariance.
There are limitations to such a method, most notably that the erasing projection is linear. Therefore there might still be information lurking in the representations that could be adversarially used. One way to partially solve that is by using rich transformations on the neural representations and see whether, after these transformations, the information is there and can be removed. This is done through a derivative of SAL, kSAL (for kernelized SAL), which uses kernel methods to create rich transformations.
Finally, it is often the case that we would like to remove information from a neural representation. Still, we might be unable to pair each representation with its corresponding attribute during training, as SAL would require. This is where the Assignment-Maximization SAL algorithm comes in to help us. It helps erase information from neural representations by looking at overall population statistics (such as the priors of different classes of protected attributes). In two iterative steps, it first (A) assigns each (projected) neural representation an attribute, and then (M) finds a projection to maximize the correlation between the attributes and the representations. By iterating between these two steps, not unlike the EM algorithm (but without a log-likelihood function), it aims at finding an assignment of a protected attribute to each neural representation, which makes them readily available for a final step.
The figure below illustrates the impact of SAL on word representations and, specifically, its effectiveness in removing gender information from a profession classification dataset. This is a dataset that demonstrates the problem of relying on gender attributes when predicting from a biography what the profession of the person in the biography is.
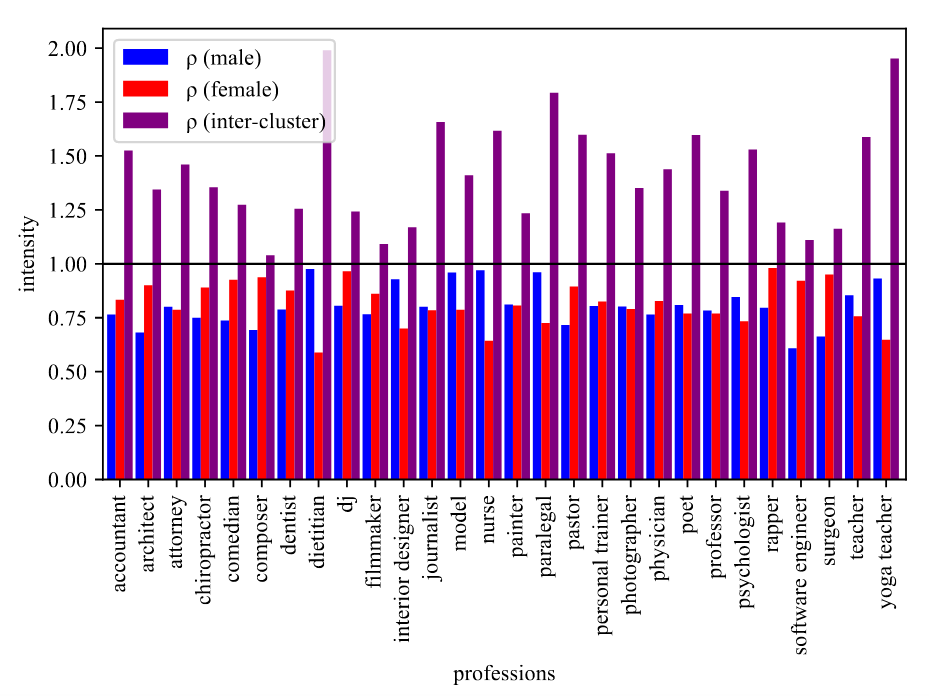
We examined how similar gender-stereotypical words (male and female) are with respect to each word in their profession cluster - male(blue)/female(red) associated words before and after we applied SAL on the representations. Similarly, we calculated inter-cluster similarity. A score higher than one means the similarities are higher after we use SAL, and a lower than one means the similarities are lower.
Our analysis revealed that, on average, words become less similar to others in their corresponding profession cluster and more similar to words in the opposite cluster after applying SAL, making it more challenging for classifiers to use gender-related information for profession classification where biased prediction may lead to unfair automated hiring procedure.
Paper
Click here for the EACL paper and here for the TACL paper.
@inproceedings{shao-23a,
author = "S. Shao and Y. Ziser and S. B. Cohen",
title = "Gold Doesn't Always Glitter: Spectral Removal of Linear and Nonlinear Guarded Attribute Information",
booktitle = "Proceedings of {EACL}",
year = "2023"
}
@article{shao-23b,
author = "S. Shao and Y. Ziser and S. B. Cohen",
title = "Erasure of Unaligned Attributes from Neural Representations",
journal = "Transactions of the Association for Computational Linguistics",
year = "2023"
}